Jun
18
The Heston Recipe: A Picture, from Fabrice Rouah
June 18, 2013 | Leave a Comment
This is an update to my first article about the Heston Recipe on the site.
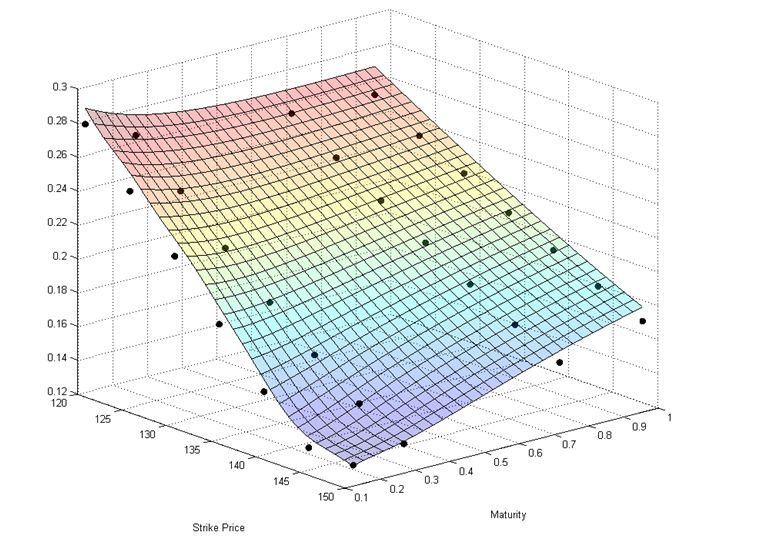
The Heston model is a mathematical formula for the call price. Similar to the Black-Scholes formula, it requires a set of observable inputs such as the spot price and strike price, the risk free rate, and the time to expiry. In place of the single parameter 'sigma' in Black-Scholes, however, the Heston model requires a number of parameters that must be estimated from market data. These parameters drive the shape of the implied volatility surface extracted from call prices generated with the model. This surface is simply a three-dimensional plot of implied volatility as it varies according to strike and to maturity.
In FX markets the implied volatility is usually symmetric in the strike direction and the pattern is often referred to as a "smile". In equities markets, however, the implied volatility is usually asymmetric and is referred to as a "smirk" or "sneer." A number of explanations have been proposed for the asymmetrical smirk, but one of the most plausible is "crash-o-phobia." According to this explanation, following the October 1987 crash, investors in equity options have been willing to pay relatively more for downside protection than for upside speculation. Consequently, out-of-the-money (OTM) puts are relatively more expensive than OTM calls. Since there is a one-to-one, monotonic, relationship between the option price and its implied volatility, the smirk is simply a reflection of this price mismatching. The Heston model is a convenient way to capture the smirk and other features of implied volatility, along a continuum of strikes and maturities.
The most common way to estimate the parameters of the model is to construct a function that calculates the distance between implied volatilities observed in the market, and implied volatilities generated by the model and matched by strike and maturity. The distance is often chosen as the squared difference between the model and market implied volatilities, and the function is the sum of all the squared differences. The parameter set is chosen as that which leads to the smallest sum, and consequently, which provides the closest fit of market implied volatilities to their model counterparts. The figure illustrates the implied volatility surface for a subset of SPY options on April 13, 2012. The market implied volatilities are represented by black dots, and the implied volatility surface generated by the Heston model, by the colored mesh. The Heston model is able to fit the smirk, and to account for the mitigation of the smirk at long maturities.
Jun
13
The Heston Recipe, from Fabrice Rouah
June 13, 2013 | 1 Comment
 Most traders are intimately familiar the implied volatilities of equity options. These implied volatilities are often smoothed to avoid the temporary spikes in the strike/maturity surface that can lead to butterfly and calendar arbitrage. Many trading desks and market makers use the Heston stochastic volatility model for smoothing.
Most traders are intimately familiar the implied volatilities of equity options. These implied volatilities are often smoothed to avoid the temporary spikes in the strike/maturity surface that can lead to butterfly and calendar arbitrage. Many trading desks and market makers use the Heston stochastic volatility model for smoothing.
To understand the genesis behind Heston model, and why it is so important, we must revisit an event that shook financial markets around the world: the stock market crash of October 1987. The consequence on the options market was an exacerbation of smiles and skews in the implied volatility surface which has persisted to this day. This brought into question the restrictive assumptions behind the Black-Scholes option pricing model, the most tenuous of which is that continuously compounded stock returns be normally distributed with constant volatility. A number of researchers since then have sought to eliminate the constant volatility assumption in their models, by allowing volatility to be time-varying.
One popular time-varying approach is to allow volatility to be stochastic. The Heston model, developed in 1993, was not the first stochastic volatility model for pricing equity options, but for mathematical and practical reasons it is by far the most popular and the most successful. It is used throughout the world by option trading desks and market makers, banks, hedge funds, and academics. It forms a crucial part of the options curriculum of financial engineering programs offered by universities across the world. The model has been refined and extended in many ways, to overcome some of the shortcomings of its original formulation. The top option valuation software companies, such as Numerix, SuperDerivatives, and Fincad, all incorporate the model into their pricing routines. My forthcoming book is devoted entirely to the model.
In short, the Heston model is one of the great success stories of mathematical finance, yet most financial professionals have never heard of it. The next time someone mentions the Heston model, you won't be wondering whether it refers to Charlton Heston, the late American actor, or Heston Blumenthal, the quirky British chef, but to Steve Heston, one of the most influential financial engineers of the modern era.
Fabrice Rouah is the author of the forthcoming book "The Heston Model in Matlab
and C#" from John Wiley & Sons.and a consultant on option pricing models.
Mar
14
Paper for Non-Statisticians, from Victor Niederhoffer
March 14, 2013 | Leave a Comment
 There's a rather direct and rather readily understandable paper that's the standard for non-statisticians trying to asses the difference between such things as test-retest correlations, difference between means of binary splits, and agreement of two successive measurement of individuals. Completely related and very similar to the binary split cart essay of Doc and me. But no consideration of sampling without replacement, small number of observations requiring a t distribution, simulation of actual distributions of differences, or adjustments for highest of n differences. Bland statistical methods for assessing agreement. Lancet 1986.
There's a rather direct and rather readily understandable paper that's the standard for non-statisticians trying to asses the difference between such things as test-retest correlations, difference between means of binary splits, and agreement of two successive measurement of individuals. Completely related and very similar to the binary split cart essay of Doc and me. But no consideration of sampling without replacement, small number of observations requiring a t distribution, simulation of actual distributions of differences, or adjustments for highest of n differences. Bland statistical methods for assessing agreement. Lancet 1986.
Fabrice Rouah writes:
Another great resource in this area is the textbook by Joseph Fleiss, Statistical Methods for Rates and Proportions, now in its 3rd edition.
Feb
8
Thoughts on Lance Armstrong, from Fabrice Rouah
February 8, 2013 | 4 Comments
I recently saw this article: "Armstrong Sued Over Prize Money" . Sure to be the first of many lawsuits against him.
 It's worth remembering that doping constitutes only a tiny part of an athlete's activities. Most of their time is spent training, in the gym, exercising, dieting, etc. You cannot transform an out-of-shape and overweight cycling wannabe (me!) overnight into a Tour winner simply by giving him dope.
It's worth remembering that doping constitutes only a tiny part of an athlete's activities. Most of their time is spent training, in the gym, exercising, dieting, etc. You cannot transform an out-of-shape and overweight cycling wannabe (me!) overnight into a Tour winner simply by giving him dope.
We all know Armstrong's story but it's worth repeating. Testicular cancer that spread to his brain and to 12 golf ball-sized tumors in his lungs; given less than 50% chance of survival; refused a cancer treatment that would damage his lungs; insisted to his doctors that he would survive return to competitive cycling when they were telling him that he would be confined to a wheelchair.
His remarkable recovery wasn't due to doping, but to his determination and will.
Feb
7
A Tau Measure of Serial Dependendence, from Victor Niederhoffer
February 7, 2013 | Leave a Comment
It is interesting and useful to measure the tendency to continuation or reversal in a series. It's particularly useful for markets because many traders like to go with or against in a period. And some measure of whether this works or not, and how it's changing provides a rudder.
The usual methods of measuring it rely on the serial correlation coefficient, but this tends to be disrupted by extreme or missing observations and doesn't have stable properties for many non-normal distributions. Non-parametric measures that rely on ranks, runs, or moves above and below the median, or curve fitting for consecutive observations have often been used. Cowles started the whole subject for stock prices by looking at sequences and reversals in consecutive prices.
A measure that I have been working with that is relatively new and has many advantages is to consider the concordances and discordances in a series. This method is based on work done by Kendall in rank correlations with his statistic, Kendall's Tau. A key article in this area that provides an excellent foundation is Ferguson, Genet and Hallin, "Kendall's tau for serial dependence" and "Bandt Ordinal Time series analysis".
The method of concordances and discordances starts with looking at 3 consecutive observations in a series. Let's call them p1, p2, and p3. If p2 > 1 and P3 > p2, that's a positive concordance. If p2< 1 and P3 < p2, that's a negative concordance. All the other rises followed by declines, or declines followed by rises are discordances. (Note that there are 6 permutations of the 3 numbers and only 2 yield concordances.)
To make it more tangible consider the levels in stocks from Friday 1/4/2013 to Friday 1/11/2013
day Date Level change rank of change
Fri 1/4/2013 1458
Mon 1/7/2013 1456 -2 2
Tues 1/8/2013 1452 -4 1
Wed 1/9/2013 1456 4 4
Thurs 1/10/2013 1467 11 5
Fri 1/11/2013 1467 0 3
To measure the momentum in the series of changes, one must compute all the consecutive one day discordances, + the number of consecutive 2 day discordances + the number of 3 day discordances. It is best to focus on the ranks. If the consecutive pairs of ranks reverse there is a discordance. If they are in the same direction, there is a concordance.
Comparing Mon to Tue and Tue to Wed, one notes a discordance.
Comparing Tues to Wed, and Wed to Thur, there is a concordance.
Comparing Wed to Thurs, and Thurs to Friday, there is a discordance.
Now start with ranks 2 days apart.
Mon and Wed and Tue and Thur are in concord.
Tues and Thur and Wed and Friday are in discord as Thur rank is higher than Tues and Friday's rank is lower than Wed.
There is one 3 day comparison. Mon and Thur, and Tuesday to Friday are in concordance. Thus, there were 3 discordances and 3 concordances. It turns out that the expected number of discordances for a time series is ( n-2) ( 3n-1 ) / 12. since n is 5 , the expected number of discordances is 3.5. An exact calculation is possible and shows that 3 or less discordances has a prob of 20%.
How can this measure be used? First, it provides a nice estimate of the degree of correlation between the consecutive values of a series. The question then arises, how can one predict subsequent momentum based on past momentum. It turns out that that there is a tendency in the series that we have looked at , for periods with high concordances to be followed by periods with high discordances, i.e. momentum changes from period to period. This would have to be quantified with the period one is interested in, a week, a month etc.
I will report further work on this in future. I would like to thank Doc Castaldo and Mike Chuprin for their kind assistance on this project.
Fabrice Rouah writes:
Very good point. Non-parametric methods are definitely preferable for financial time series that rarely meet the normality or linearity assumptions required of many parametric methods. Another example of parametric methods are t-tests and ANOVA. To compare returns between different groups one is better off using their non-parametric counterparts, namely the tests of Wilcoxon, Mann-Whitney, Kruskal-Wallis and many others.
Jan
31
Web Site for Free Derivatives Pricing Code, from Fabrice Rouah
January 31, 2013 | Leave a Comment
Hi everyone,
I've created www.Volopta.com, which contains free derivatives pricing code in a variety of languages, such as Matlab, C++, etc.
Feel free to distribute the link to anyone you think might be interested.
Thanks!
Fabrice
Jan
25
What Vol for an American Option? from Fabrice Rouah
January 25, 2013 | 1 Comment
The next time your dealer quotes the implied volatility of an American option, be sure to ask "is that trinomial, BAW, or something else?" Implied volatilities are obtained by matching the market price of an option to its corresponding model price, and finding the value of volatility that equates both. Implied volatilities are therefore dependent on the model used. For European options the industry-standard implied volatility model is the Black-Scholes model. Implied volatilities from European options should be denoted "Black-Scholes implied volatilities" but since there is no ambiguity about the model used to extract them they are simply known as "implied volatilities." Consequently, given the correct inputs such as the strike price and underlying spot price an operator should, in principle, be able to replicate the same implied volatility as that which has been quoted, up to rounding-off error.
For American options (example) the situation is different as there is no industry-standard model for pricing American options, even under Black-Scholes assumptions. The available models include binomial trees and trinomial trees of various sorts, the Barone-Adesi and Whaley approximation (BAW) and its variants, the Longstaff and Schwartz algorithm, and many others. Hence, without the choice of model being used to extract an implied volatility, a trader cannot obtain the same quoted implied volatility. Even given the choice of model, approximation error (such as the number of time steps used in the tree, or simulation noise, for example) would preclude an exact replication of the quoted implied volatility.
One very promising method to valuing American puts has been proposed by Alexey Medvedev and Olivier Scaillet in their 2010 paper, published in the Journal of Financial Economics (link). Their method takes the form of an infinite expansion with analytic terms, truncated in practice to usually five terms or less. Being of closed form, prices are produced very fast. An implied volatility extracted with this model could be replicated, provided the number of expansion terms is specified.
Fabrice Rouah is the author of the book "The Heston Model in Matlab and C#" to be published in early 2013 by John Wiley & Sons.
Archives
- June 2026
- May 2026
- April 2026
- March 2026
- February 2026
- January 2026
- December 2025
- November 2025
- October 2025
- September 2025
- August 2025
- July 2025
- June 2025
- May 2025
- April 2025
- March 2025
- February 2025
- January 2025
- December 2024
- November 2024
- October 2024
- September 2024
- August 2024
- July 2024
- June 2024
- May 2024
- April 2024
- March 2024
- February 2024
- January 2024
- December 2023
- November 2023
- October 2023
- September 2023
- August 2023
- July 2023
- June 2023
- May 2023
- April 2023
- March 2023
- February 2023
- January 2023
- December 2022
- November 2022
- October 2022
- September 2022
- August 2022
- July 2022
- June 2022
- May 2022
- April 2022
- March 2022
- February 2022
- January 2022
- December 2021
- November 2021
- October 2021
- September 2021
- August 2021
- July 2021
- June 2021
- May 2021
- April 2021
- March 2021
- February 2021
- January 2021
- December 2020
- November 2020
- October 2020
- September 2020
- August 2020
- July 2020
- June 2020
- May 2020
- April 2020
- March 2020
- February 2020
- January 2020
- December 2019
- November 2019
- October 2019
- September 2019
- August 2019
- July 2019
- June 2019
- May 2019
- April 2019
- March 2019
- February 2019
- January 2019
- December 2018
- November 2018
- October 2018
- September 2018
- August 2018
- July 2018
- June 2018
- May 2018
- April 2018
- March 2018
- February 2018
- January 2018
- December 2017
- November 2017
- October 2017
- September 2017
- August 2017
- July 2017
- June 2017
- May 2017
- April 2017
- March 2017
- February 2017
- January 2017
- December 2016
- November 2016
- October 2016
- September 2016
- August 2016
- July 2016
- June 2016
- May 2016
- April 2016
- March 2016
- February 2016
- January 2016
- December 2015
- November 2015
- October 2015
- September 2015
- August 2015
- July 2015
- June 2015
- May 2015
- April 2015
- March 2015
- February 2015
- January 2015
- December 2014
- November 2014
- October 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013
- September 2013
- August 2013
- July 2013
- June 2013
- May 2013
- April 2013
- March 2013
- February 2013
- January 2013
- December 2012
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- June 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- August 2011
- July 2011
- June 2011
- May 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- March 2010
- February 2010
- January 2010
- December 2009
- November 2009
- October 2009
- September 2009
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- March 2009
- February 2009
- January 2009
- December 2008
- November 2008
- October 2008
- September 2008
- August 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- January 2008
- December 2007
- November 2007
- October 2007
- September 2007
- August 2007
- July 2007
- June 2007
- May 2007
- April 2007
- March 2007
- February 2007
- January 2007
- December 2006
- November 2006
- October 2006
- September 2006
- August 2006
- Older Archives
Resources & Links
- The Letters Prize
- Pre-2007 Victor Niederhoffer Posts
- Vic’s NYC Junto
- Reading List
- Programming in 60 Seconds
- The Objectivist Center
- Foundation for Economic Education
- Tigerchess
- Dick Sears' G.T. Index
- Pre-2007 Daily Speculations
- Laurel & Vics' Worldly Investor Articles
{kind=link}